
TabDDPM: DDPM을 이용한 테이블 데이터 생성
DDPM을 활용한 테이블 데이터 생성 관련 Akim Kotelnikov et al.의 논문소개입니다. 저자의 논문만이 아니라 블로그에서도 많은 내용을 참고하여 적었습니다.
테이블 데이터 생성
테이블 데이터 생성에 대한 논문들이 많은데요. 아무래도 학습데이터로 활용될 때 개인 정보 등의 문제로 합성 데이터를 활용하고자 하는 목적이 큽니다.
테이블 합성데이터의 평가
생성 기술에서 늘 가장 어려운 부분이 평가가 아닐까 싶습니다. 다른 supervised 방법 혹은 특정 태스크들은 정답이 있어 비교평가가 가능하지만, 생성은 분포를 학습하는 것이기 때문에 얼마나 분포를 잘 학습했나 하는 모호한 평가기준 때문입니다. 그래서 1) 다른 태스크에 합성데이터를 적용해서 유의미한 결과를 이끌어내는지 2) 실제 데이터와의 분포 비교 평가를 하는 것이 일반적이 방법입니다.
다른 태스크에 합성데이터 적용하여 efficacy/utility(효험) 평가
예를들어 분류(classification) 태스크에 대해 실제데이터만으로 학습했을 때와 합성데이터만으로 학습했을 때, 실제 데이터에 대한 분류의 정확도가 유사할 수록 사실과 비슷한 합성데이터가 생성되었다고 판단할 수 있습니다.
합성데이터의 분포 평가
합성 데이터와 실제 데이터 feature의 분포의 유사성을 평가하는 방법입니다. 이는 일반적인 생성 모델에서 많이 사용되는데요. 제가 생각했을 때, 테이블 데이터에서 사용되는 다른 분포 평가는 아래의 프라이버시 평가입니다.
privacy 평가
테이블 데이터에서 해결해야 하는 중요한 문제가 프라이버시인데요. 이미지의 경우 합성데이터의 품질이나 프라이버시를 정성적으로 한눈에 평가할 수 있지만, 테이블 데이터는 평가가 더 까다로운 부분이 있습니다. 특히, 합성된 테이블이 실제 데이터와 거의 같은 데이터라면 프라이버시 문제가 전혀 해결이 되지 않는 문제가 발생할 수 있습니다. 그래서 테이블 데이터의 프라이버시 품질을 평가하기 위해 [1]에서 제안한 Distance to Closest Record의 방법을 본 논문에서도 활용했다고 합니다. 이는 가장 가까운 실제데이터와의 거리를 말하며, 이 거리가 커질수 있도록 학습하고자 했다고 합니다.
Diffusion model
Diffusion model은 데이터로부터 노이즈를 더해가는 forward 방향의 반대인 inverse 방향을 학습해, 노이즈로부터 가우시안 분포를 더하여 denoising해 합성데이터를 생성하는 기법입니다. 그중에서도 이 논문에서 근간으로 하는 DDPM[2] 논문은 기회가 된다면 블로그에서 한번 다뤄보도록 하겠습니다. 본 논문에서는 categorical(범주형) 데이터를 합성할 수 있는 multinomial diffusion[3] 기법을 차용하였습니다. 따라서 numerical data와 categorical table data를 모두 합성할 수 있는 것이 이 논문의 주요한 기여점입니다.
참고로, numerical data는 예를들어 몸무게, 키와 같은 연속적인 데이터를 의미합니다. categorical data는 혈액형, 성별과 같이 불연속적인 라벨링이 가능한 데이터를 의미합니다.
본 논문을 활용한다면, 어떤 사람의 혈액형, 키, 몸무게, 직업군과 같이 연속적(키, 몸무게), 불연속적(혈액형, 직업군) 데이터를 동시에 합성할 수 있겠죠.
TabDDPM
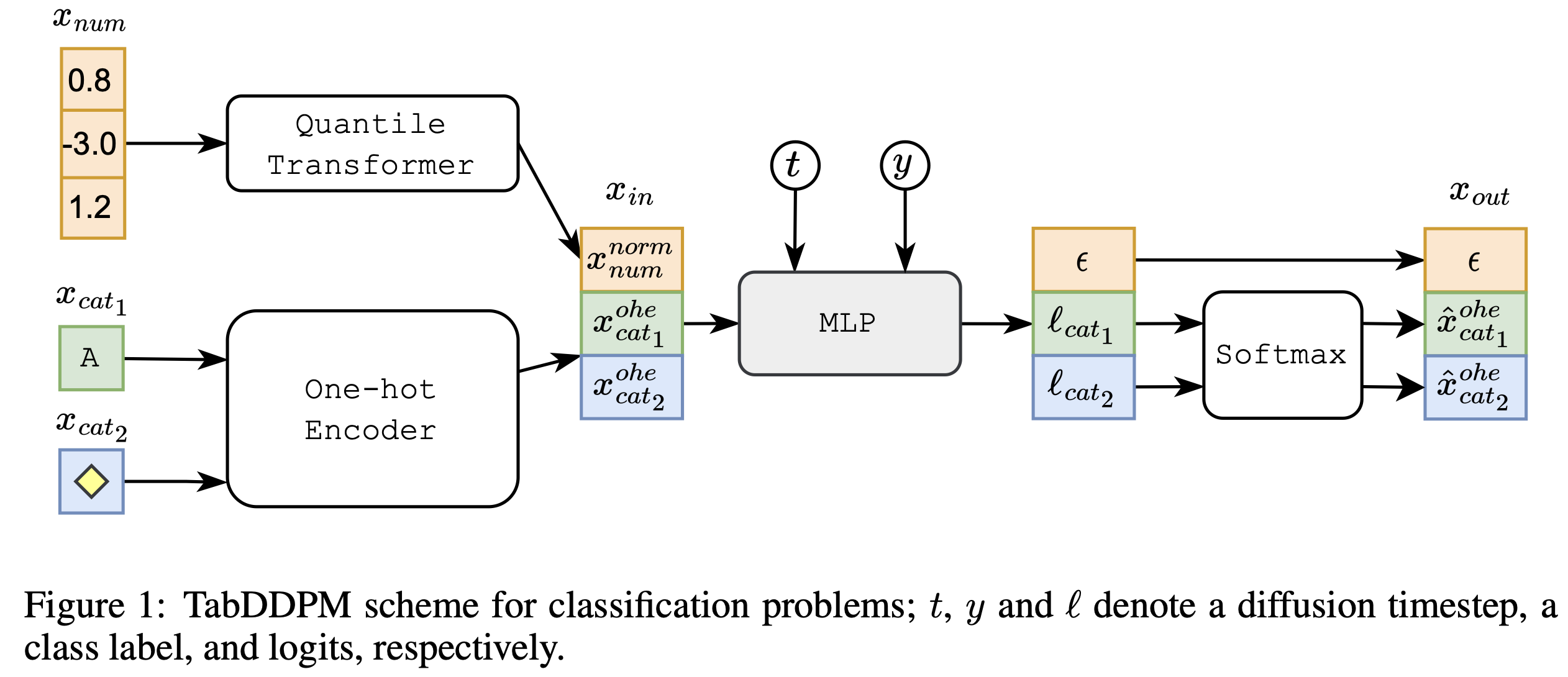
출처: [TabDDPM]](https://arxiv.org/abs/2209.15421)
위 이미지에서 볼 수 있듯 numerical data(3차원)와 두 categorical data를 합성하는 프레임워크인데요.
먼저 numericlal noise에는 quantitle transformer를 달아 입력값이 사용자가 지정한 분포 안에 들어가게 해주고, 카테고리 노이즈는 one hot encoding 해주어 MLP 에 넣습니다.
본 MLP는 타임스텝마다 Gaussian diffusion을 활용한 numerical data 합성을 위해 epsilon과 softmax를 거쳐 one hot encoding된 categorical 데이터를 생성합니다.
참고문헌
[1]CTAB-GAN: Effective Table Data Synthesizing, Z.Zhao et al., ACML(2021)
[2]Denoising diffusion probabilistic models, J. Ho et al., NeurIPS(2020)
[3]Argmax flows and multinomial diffusion: Learning categorical distributions, E. Hoogeboom et al., NeurIPS(2021)
# tabular data generation # 테이블 데이터 생성